Hardware assembly, OS and comunication set-up
Ivan Rossi, Piero Fariselli, Pier Luigi Martelli, Gianluca Tasco
CIRB Biocomputing Unit, Universita` di Bologna, Via Irnerio 48, 40122
Bologna
1. Hardware
According to the Beowulf philosophy, th CIRB cluster prototype have been
assembled using Components-Off-the-Shelf (COTS). The cluster is formed by
the following main parts: the master front-end machine, four computing
nodes (slaves) , the interconnection subsytem and console.
Front-end:
CPUs: two Pentium III/700 MHz (Coppermine)
RAM: 512 Mb SDRAM
Storage:
Adaptec AIC-7896/7 Ultra2 SCSI controller,
Quantum ATLAS IV 9 Gb SCSI Hard Disk,
LG CED-8080B EIDE CD-RW (as backup unit),
CD-Rom.
NICs:
Realtek RTL-8029 PCI (outbound to the Internet)
Intel EtherExpress Pro/100 PCI (100 MBps inbound)
Slaves:
CPUs: two Pentium III/500 MHz (Katmai)
RAM: 256 Mb SDRAM
Storage:
Symbios 53c856 SCSI III controller,
Quantum ATLAS IV SCSI 9 Gb Hard Disk,
NICs:
Intel EtherExpress Pro/100 PCI (100 MBps inbound)
Interconnection:
Intel Express 520T FastEthernet switch (1 Gbps
backplane).
Console:
Maxxtro 6-port keyboard-video-mouse (KVM) switch
IBM PowerDisplay 17" monitor
PS/2 Keyboard and 3-buttons mouse
The slave machines were already available at the CIRB Biocomputing unit.
The front-end and the FastEthernet and KWM switches have been acquired in
order to assemble the cluster.
Comments
The front-end machine has been equipped with faster CPUs and and a larger
quantity of RAM with respect to the slave nodes, because it suffers from
higher loads since it has to support the interactive sessions of the users,
X-windows services, Network File System (NFS) export services to the
nodes. Furthermore it is loaded by IP traffic from both the cluster
private network and the Internet.
For the private-network interconnection system FastEthernet has been
selected instead of GigabitEthernet or Myrinet.
GigabitEthernet cards and switches are the newest entry in the market and
suffers from and high prices, at least a factor of five-seven difference
when compared to their FastEthernet counterparts. However the most
important factor against its adoption is, in our mind its limited support
in the Linux kernel, in terms of network drivers available. The situation
is supposed to get better in a short time since many major vendors
(including Intel) are now supporting this technology. We expect
GigabitEthernet to be the way to go, as soon as the technology matures some
more.
As opposed to GigabitEthernet, the Myrinet interconnections has been
supported in the Linux kernel since the 2.0 series, however it suffers from
being a single-vendor technology: only Myricom Inc. provides Myrinet
hardware. The prices for both NICs and switches are 10-15 times higher than
their FastEthernet equivalent, meaning that the price of the NIC only can
amount to almost half of the total price for a compute node. Myrinet has
been discarded based on budget limitations.
Since the network traffic is expected to be much lower on the Internet side
of the network, special care has been taken to select the best-performing
network interface card available to our budget. A survey of users group on
the Internet, and in particular of the archives of the BEOWULF mailing list
(
http://www.beowulf.org/pipermail/beowulf/
or more information), that is
devoted to the discussion about all the aspects of Beowulf-class systems
assembly and usage, indicated that one the most appeciated NIC in terms of
price, reliability and low latency is the Intel "EtherExpress Pro/100" ,
which has been acquired and installed on all the machines of the cluster,
also because of its high availability through almost any vendor.
A KVM switch is not strictly necessary in order to run a Beowulf cluster,
howeevr it simplyfies install and maintenance operations by allowing a
centralized, quick and practioal direct access to the console terminal of
every machine in the cluster, which can be invaluable if a problem arises.
An EIDE CD/RW has been chosen as a the main backup unit for users files and
data, due to its low cost and to the fact that CD-ROM are much more
sturdier and dependable than magnetic tapes for long-term data storage.
Their main drawback is their relatively limited capacity (700 MB), however
SCSI tape backup units are already available at CIRB Biocomputing Unit and
they can be connected to the front-end SCSI bus, should the necessity
arise. The resulting assembly is shown in the photo included hereafter.
2. OS and communications
The Linux operating system has been widely used and tested to build
high�performance computing cluster using the Intel x86 platform.
Furthermore, the price is right: either free or extremely inexpensive,
depending on the distribution that it is used. We tested two different
distribution: a general-purpose distribution, the widely-used RedHat Linux
6.2, and Scyld Beowulf, a recently�released distribution designed for the
implementation of parallel computers.
Redhat 6.2 + Kickstart
Redhat has some advantage over other Linux distributions due to the RPM
method of packaging software and to the Kickstart unattended installation
method.
The first step for the beowulf cluster assembly is the installation of the
front�end machine. Partitioning of the hard disk followed by a standard
full installation of all the available packages on the distribution CD�ROM
has been performed. After the installation a DHCP server has been
configured, so that the cluster slave nodes will dinamically get their
network configuration parameters at boot. Network file system (NFS) sharing
of the CD-ROM and of the /usr/local and /home filesystems, where local
applications and user data will reside, has been activated.
It is of paramount importance to secure the network installation on the
front�end by configuring it as a network firewall, since a security breach
in it will compromise the entire cluster. Only secure-shell
(http://www.openssh.org
) logins and file transfers have been allowed from
the Internet to the cluster. The standard Linux IPCHAINS and TCP_wrappers
tools has been used for this purpose. This strategy showed its importance
really soon: several intrusion attempts and TCP port scans have been logged
in the first couple of days after the installation, some of them whom might
have been successful on a plain RedHat installation.
On the slave nodes the installation is somewhat different: first these are
machines that do not have a CD drive, so the NFS install from the shared CD-
ROM has to be used. One of the slave node has been designated as the
"golden standard" and a supervised NFS installation and configuration has
been done for it. A stripped-down installation that includes only basic
networking fonctionality plus client DHCP, NIS and NFS services, rsync,
sshd, and MPI support has been performed. The end result of this process
is a cluster of two machines: the front-end and the "golden standard" lave.
The final step is the creation of the Kickstart file by means of the
"mkkickstart" utility. The file generated contain a description of the
installation process experssed in the Kickstart syntax. A example of the
file is included below:
# "Golden node" kickstart file
lang en
network --dhcp
nfs --server 192.168.1.1 /mnt/cdrom
keyboard us
zerombr yes
clearpart --all
part / --size 500M --grow
part /tmp --size 2048M --grow
part swap --size 256M
install
mouse ps/2
timezone --utc Europe/Rome
rootpw --iscrypted X7hcxtGPw/A.
lilo --location mbr
%packages
@ Networked Workstation
rsync
rdate
%post
rpm -i ftp://192.168.1.1/usr/local/rpms/openssh.rpm
rpm -i ftp://192.168.1.1/usr/local/rpms/mpich.rpm
echo "192.168.1.1:/home /home nfs defaults" >>/etc/fstab
echo "192.168.1.1:/usr/local /usr/local nfs defaults" >>/etc/fstab
This file can then be used as input for the RedHat kickstart installation
process, allowing for a very quick reinstallation of the golden node
machine, should the necessity arise, but also for fast cloning of it on
all the other slave machines, thus generating the entire cluster.
The main drawback of this kind of installation appears during maintenance:
in general every change in the configuration must be replicated
consistently on every machine. For example in order to upgrade some
software package, you have to make the RPM file available to all the
machines, that can be done with up an RPM archive on the front-end and run
rpm on each node, that is easily done by scripting, however should
something go wrong, version skew problems will arise. Furthermore user id,
password and groups need to be syncronized across the entire cluster, but
NIS services showed instabilities, thus syncronization has been achieved by
means of rsync transfers of the relevant files and scripting.
Scyld Beowulf
Scyld Beowulf includes an enhanced Linux kernel, libraries, and utilities
specifically designed for clustering. Furthermore this distribution
provides a "single system image" through a kernel extension called Bproc,
that provides cluster process management by making the processes running on
cluster "Computation Node" computers visible and manageable on the front-
end "Master Node". Processes start on the front-end node and migrate to a
cluster node, however the process parent-child relationships and UNIX job
control are maintained with migrated tasks.
This unified "cluster process space", provides the capability to start,
observe, and control processes on cluster nodes from the cluster's front-
end computer
Another interesting feature of the Bproc system is its low latency
decreases time to start processes remotely. Its process migration times has
been measured to be of ten milliseconds, that represent an order of
magnitude improvement over other job spawning methods. Scyld Beowulf ships
with a customized version of the popular MPICH implementation of the MPI
message passing library that has been modified modified to take advantage
of the process creation and management facilities provided by the Bproc
system. Moreover the supplied Linux kernel and GNU C library have bben
patched in order to support Large File Summit (LFS) and 64 bit file access
on the ext2 filesystem. Several includes utilities (Basic text utilities,
scp, ftp client and server) have also been modified to take advantage of
it.
Another feature of the single-system image provided by Bproc is that
cluster slave nodes are not required to contain any resident applications.
The dynamically-linked libraries are cached locally on the slave node ,
while the executables are started on the front end and then moved to the
slave through Bproc system. This means that the cluster can be formed also
by a master and several diskless slave. If present, the slave hard disks
are used for application data and cache. Furthermore part of the available
storage space on the slaves may also be shared with the whole cluster
through some sort of cluster file system such as AFS
(
http://www.openafs.org/
), PVFS (http://parlweb.parl.clemson.edu/pvfs/
),
and GFS (
http://www.sistina.com/gfs/
).
One huge advantage of the single system image approach from the sytem
manager point of view is the great semplification in installation,
administration and maintainence of the cluster. Scyld Beowulf installation
is easy: it is mainly a matter of installing the distribution on the front-
end, which it is done in the same way as for a RedHat Linux 6.2
installation. After that it is necessary to create a boot image for the
slaves, to assign unique network numbers to the slaves and to define the
partitioning scheme for the slaves hard drives . At their next boot, the
slave nodes will join the cluster, download the appropriate kernel and
cache locally the DLLs.
Maintenance is simplified too, because only the codes on the front end need
to be upgraded, since the slaves will dinamically get what they need from
the it. This also eliminates application version skew.
The same network security issues discussed for RedHat 6.2 apply to the
Scyld distribution too.
System testing : networking
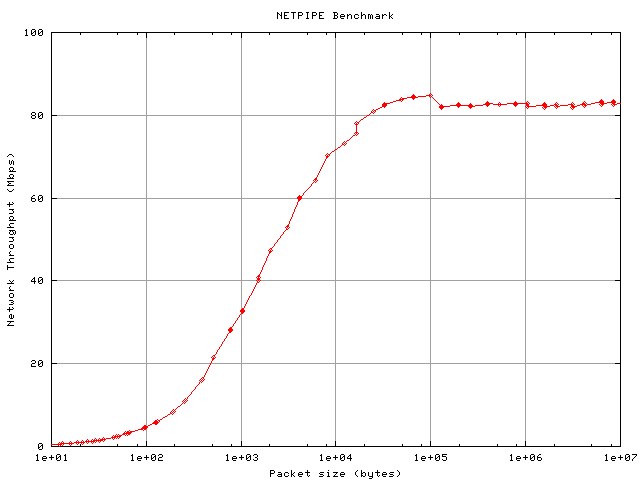
The cluster Communication system performance have been evaluated by means
of the MPI variant of the NetPIPE benchmark (NPmpi). NetPIPE
(
http://www.scl.ameslab.gov/netpipe/) is a protocol independent performance
tool that can measure the network performance under a variety of
conditions. By taking the end-to-end application view of a network, NetPIPE
can shows the overhead associated with different protocol layers. Netpipe
has been used here to determine the network's effective maximum
throughputand saturation level when using the MPI communication layer. The
graph clearly shows that the optimal
throughput is attained when large packet size are transmitted. In this
conditions a maximum throughput of 84.5 Mbps has been reached corresponding
to a 64 kb packet size. Larger packets cause a slight network performance
degradation, with a saturation value of 83 Mbps, out of a theoretical
value of 100 Mbps.
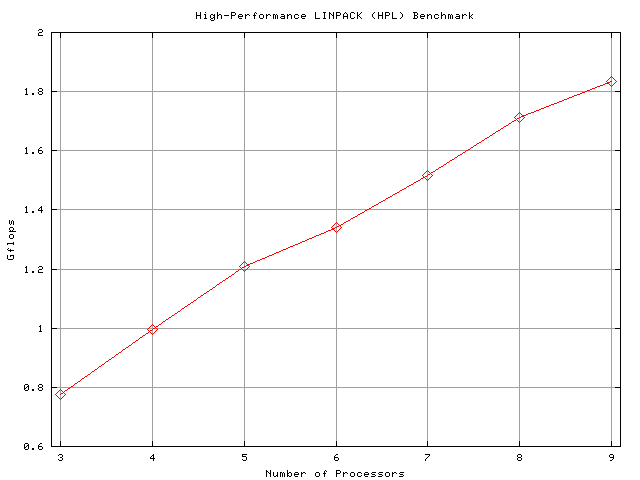
3. System testing : Overall performance
The overall cluster performance has been measured using the standard High
Performance LINPACK (HPL) benchmark (
(
http://www.netlib.org/benchmark/hpl/
).
This is a software package that solves a (random) dense linear system in
double precision (64 bits) arithmetic on distributed-memory computers. The
HPL package provides a testing and timing program to quantify the accuracy
of the obtained solution as well as the time it took to compute it. This
test is a widely recognized standard to monitor supercomputer speed: the
Top500 list (
http://www.top500.org/
), that every six months reports what
are the 500 fastest computer systems on Earth uses the HPL results as a
performance measure in ranking the computers. A matrix size of 9000 has
been used in the HPL scaling test. Using a larger matrix size (11000) a
peak performance of 1.97 GFlops has been attained. During the tests, the
network switch has been continuosly monitored for backplane saturation. The
situation never occured: network usage never exceeded 50% of the backplane
saturation value.
Conclusion
The implementation obtained using the Scyld Beowulf distribution is much
more convenient to mantain than the one obtained using the general-purpose
distribution RedHat Linux, while the installation is simple in both cases.
A working small Beowulf cluster has been deployed at the CIRB Biocomputing
Unit of the University of Bologna, reaching the planned milestone for the
workpackage.
HOMEPAGE